Big Pipe: streaming e composição de páginas
Há muito tempo o time de engenharia do Facebook escreveu um post sobre uma técnica, conhecida como Big Pipe, que permitiu que eles melhorassem muito a performance das páginas da rede social. Esse ano, o Linkedin fez uma outra apresentação sobre a mesma técnica e como eles tiraram proveito para melhorar a performance de suas páginas.
Para quem chegou até aqui e não leu o post ou viu a apresentação, o problema basicamente é o seguinte: as páginas das duas empresas são tão complexas que se transformaram em gargalos de evolução dos projetos. No Linkedin, por exemplo, uma das páginas era tão grande que estourava a memória na hora de transformar uma JSP em um Servlet :). E esse é um problema realmente mais grave. Uma outra situação mais comum, é acabarmos com páginas usando vários includes ou várias tag files, sinal de um alto grau de complexidade. Caso use um framework MVC, estilo o VRaptor, pode dar uma olhada em métodos dos seus controllers cheios de result.include(...). Isso quer dizer que sua view está precisando de muitos objetos para ser montada, o que é um mal cheiro de código.
Existem algumas abordagens comuns para lidar com esse problema. Por exemplo, quebrar a página em várias e criar uma página principal com vários iframes. Em um exemplo hipotético, poderíamos quebrar a home da caelum da seguinte forma:

<html> <head> <link ...> <script src=".."></script> </head> <body> <!-- Conteudo da pagina--> <iframe src="courses"/> <iframe src="calendar"/> <iframe src="blog"/> <!--resto do conteudo--> </body> </html>
Uma outra abordagem é ter a mesma página principal e fazer várias requisições ajax para ir buscando os conteúdos necessários para a montagem. Por mais que essas soluções resolvam o problema das páginas muito complicadas, um novo problema é gerado. O lado cliente fica responsável por fazer os requests de cada trecho de página, ou seja, o cliente é onerado por conta de um problema gerado no servidor. Cada trecho da página separado em um iframe ou carregado por ajax resulta em um novo request para o servidor:

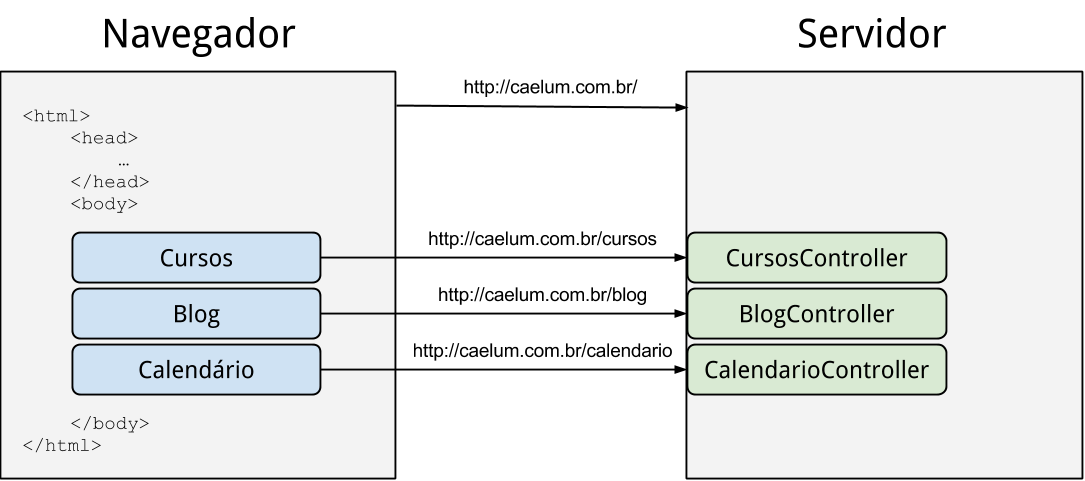
É importante considerar que cada request feito do navegador ao servidor tem um custo razoável na performance de carregamento da página, pois cada requisição http requer que o navegador perca tempo abrindo um novo socket TCP com o servidor remoto. Sabemos que minimizar o número de requisições ao servidor é uma das práticas de otimização web mais importantes, como destacado neste post.
Com isso, as soluções de ajax e iframes se tornaram inviáveis para o Facebook. A equipe da rede social desenvolveu uma nova abordagem de quebrar uma página em várias: ao invés de deixar o lado cliente executar vários requests, o servidor fica responsável por fazer os vários requests e montar a página final. Assim, o navegador executa apenas uma requisição ao servidor que fica encarregado de construir a página com diversos requests locais:

Pegamos carona nessa idéia e criamos um plugin para o VRaptor que permite fazer exatamente a mesma coisa. Confira o exemplo de página abaixo:
<html> <head> <link ...> <script src=".."></script> </head> <body> <!-- Conteudo da pagina--> <div class="big-container home-secao" id="courses-pagelet"> </div> <div class="big-container home-secao" id="blog-pagelet"> </div> <div class="big-container home-calendario" id="calendar-pagelet"> </div> <!--resto do conteudo--> </body> <vraptor:stream> <vraptor:page url="courses"/> <vraptor:page url="calendar"/> <vraptor:page url="blog"/> </vraptor:stream> </html> Por debaixo do pano, tudo que não está dentro da tag stream será enviado imediatamente para o servidor. O plugin fica responsável por fazer um request para cada url passada e, na medida que os conteúdos forem sendo devolvidos, eles vão sendo enviados para o cliente. Para melhorar, todos os requests são feitos em paralelo e são enviados para o cliente na medida que vão chegando. O que leva a seguinte pergunta: caso o calendário dos cursos seja devolvido antes dos últimos posts no blog, como fazemos para posicioná-los corretamente?
Essa responsabilidade fica dentro do trecho de página devolvido, também chamado de Pagelet nos frameworks que implementam esta técnica. Perceba que na página principal deixamos algumas divs com com ids específicos.
<div class="big-container home-secao" id="courses-pagelet"> </div> <div class="big-container home-secao" id="blog-pagelet"> </div> <div class="big-container home-calendario" id="calendar-pagelet"> </div>
Agora o próprio pagelet é capaz de pegar o html gerado e posicionar no lugar correto.
<noscript id="courses-content"> <div class="home-empresas"> <h2 class="home-subtitulo">Quem já treinou aqui</h2> <ul class="home-empresas-lista"> <li class="sp-home-petrobras home-empresa">Petrobras</li> <li class="sp-home-samsung home-empresa">Samsung</li> </ul> </div> <div class="home-depoimentos"><h2 class="home-subtitulo">O que os alunos falam</h2>
<div class="curso-depoimentos"> <div class="depoimento"> <blockquote>O treinamento dado pela Caelum foi fundamental e suficiente para viabilizar a implatação do Scrum em minha equipe de Dev. </blockquote> </div> </div> </div> </noscript>
<script> var pagelet = document.getElementById("courses-content"); document.getElementById("courses-pagelet").innerHTML = pagelet.textContent||pagelet.innerHTML; </script> Existem 3 grandes vantagens nessa abordagem. A primeira é que o servidor consegue devolver alguma coisa para o cliente de uma maneira bem mais rápida, pois não precisa esperar processar todos os dados para montar a página. Ainda nessa linha, o servidor pode inclusive decidir em priorizar algum conteúdo, por exemplo no Facebook, geralmente a timeline é a primeira coisa a aparecer. A terceira vantagem é a manutenção dos códigos responsáveis por gerar os pagelets. Cada trecho de página ficará bem menor e muito mais fácil de testar.
Analisando mais a fundo, essa quebra já é bem praticada nos sistemas. Dividir o projeto em vários serviços web já é uma técnica muito utilizada no backend, agora estamos expandindo a mesma idéia para as suas páginas, afinal de contas elas são tão importantes quanto o resto :). Já começamos a utilizar técnica em um de nossos projetos, o GUJ. Atualmente existe a home padrão e a que utiliza o plugin. Com o firebug ou o chrome tools aberto, acesse as duas e veja as diferenças!
Guilherme Silveira vai fazer uma apresentação na QCon do Rio de Janeiro onde ele apresentará os detalhes de implementação dessa técnica! Caso esteja por lá, não perca!